

Motivation 动机
今年6月份加入喔噻收钱吧之后的第一个项目,多渠道推送系统,之后会写一系列的文章去描述这个系统.这一篇所要讲述的是,多渠道推送系统的核心是一个高性能的推送执行器。
它由两部分构成,基础任务调度框架和具体的推送任务执行worker,主要用于发送推送请求到第三方服务器,如个推,小米,华为,apns,解耦推送的RPC业务和推送的执行。
Core Parameters 核心指标
核心的性能指标是单位时间发送到第三方的消息数,即QPS,在测试中可以使用mock服务器。
另外其他的目标:
- Low CPU load: 低 CPU 占用
- Low Mem usage: 低内存占用
- precise flow control: 精确的流程控制
- Elegant and fine-grained error handle: 优雅的以及细粒度的错误处理机制
- Robustness: 强大的容错
- Semantic correct: 语义正确,如停止后,没有消息停留在内存里没被处理
Arch 框架架构设计
broker: 接收消息。目前支持redis以及aliyun_mnsmanager: 捕获worker池中空闲的worker,给他们分发任务worker: 负责具体执行任务
在设计框架的时候,我考察了几种不同的实现:
worker处理任务同时监听消息队列,这种情况,当worker处理能力较弱,需要大量worker的时候会导致连接消息队列的连接数很大,并且需要设计全局锁来控制任务空闲时对MQ的大量无用操作broker获取消息以后,每次新建一个Thread或者Fiber/Goroutine来处理消息,这种方法并发量可以做到很高。但是对于资源的消耗难以精确控制,同样需要引入线程池的概念来限制并发数
所以我们最初采用的是,使用单个Goroutine去MQ获取消息(Fetch),删除消息使用单manager同步删除,对于mns队列自适应消息处理时长使用并发Goroutine的方式进行(这都造成了之后QPS上不去的结果)
QPS从20-200的优化
9月28日,豪哥回复邮件说,框架的处理能力只能达到QPS~20,无法满足上线的要求
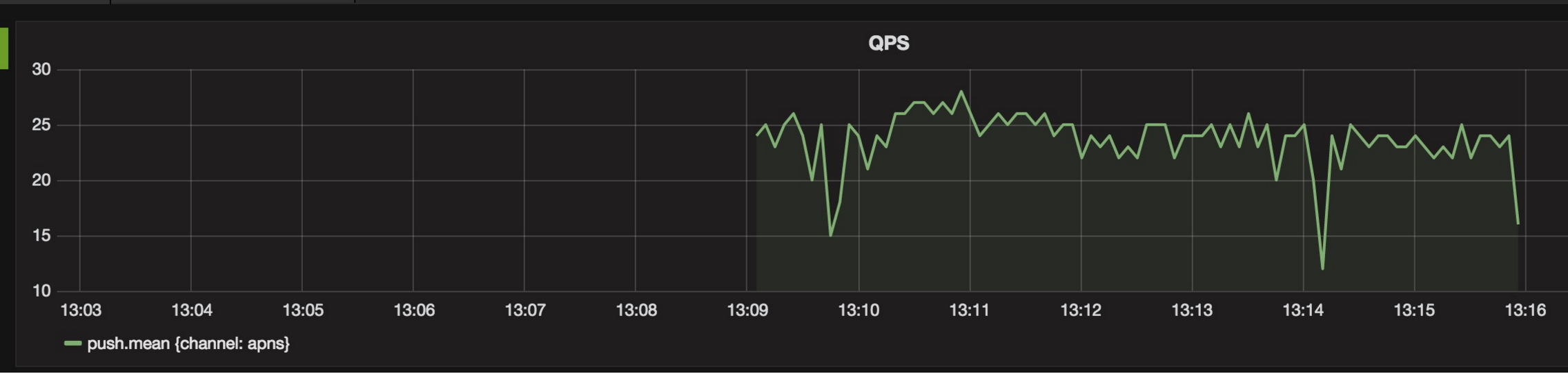
随后我们针对APNS worker的处理机制和worker的能力进行了相关的测试和优化
1. 日志输出的优化
之前我们的框架中有很多这样的打日志的代码
logger.Info(fmt.Sprintf("msg process time",))
通过字符串的拼接来进行日志输出,在性能敏感的情况下,这很容易造成QPS下降,一句日志输出的语句会占用10-30ms的执行时间,从而导致整体QPS下降
尤其是logger.Debug这样的Debug语句也会去拼接字符串,这在java中使用slf4j的时候也是一个容易犯错的地方
uber-go/zap框架推荐我们使用如下的输出语句
logger.Info("Failed to fetch URL.",
zap.String("url", url),
zap.Int("attempt", tryNum),
zap.Duration("backoff", sleepFor),
)
通过结构化的输出和合理的对象分配,降低日志操作的时间,一次日志操作性能大约能在us量级
参见https://github.com/uber-go/zap#performance
2. IO 性能
在APNS worker中,每条消息都会调用unix.Access来检查相应的iOS证书文件是否存在,所以我们怀疑是不是这个操作会占用大量的执行时间,我们用以下脚本来测试unix.Access以及os.Stat的性能
import os, os.path, sys, time
if not len(sys.argv) in (2, 3):
print "Usage: %s dir_to_scan [num_tests]" % (sys.argv[0],)
sys.exit(1)
num_tests = 5
if len(sys.argv) == 3:
try:
num_tests = int(sys.argv[2])
except ValueError:
print "num_tests must be an integer!"
sys.exit(1)
for testnum in xrange(num_tests):
start = time.time()
mtimes = []
for root, dirs, files in os.walk(sys.argv[1]):
for file in files:
path = os.path.join(root, file)
try:
mtimes.append(os.stat(path).st_mtime)
except OSError:
pass
end = time.time()
calls = len(mtimes)
print "%i files in %f seconds: %f files/second" % (calls, end - start, float(calls) / (end - start))
我们发现对文件的存在检测的性能大于为40k ops/s,一次操作执行时间在25us上下,对于框架的性能影响不大,但仍然是一个可优化的点,目前我们把文件的stat结果用map做了缓存,用RWLock来做保护
有益的一篇参考: On Linux, is access() faster than stat()?
当然在运行过程中不要用互斥锁也是一个重要的点
再之后的性能优化,我们将借助于Flame Graph来实现
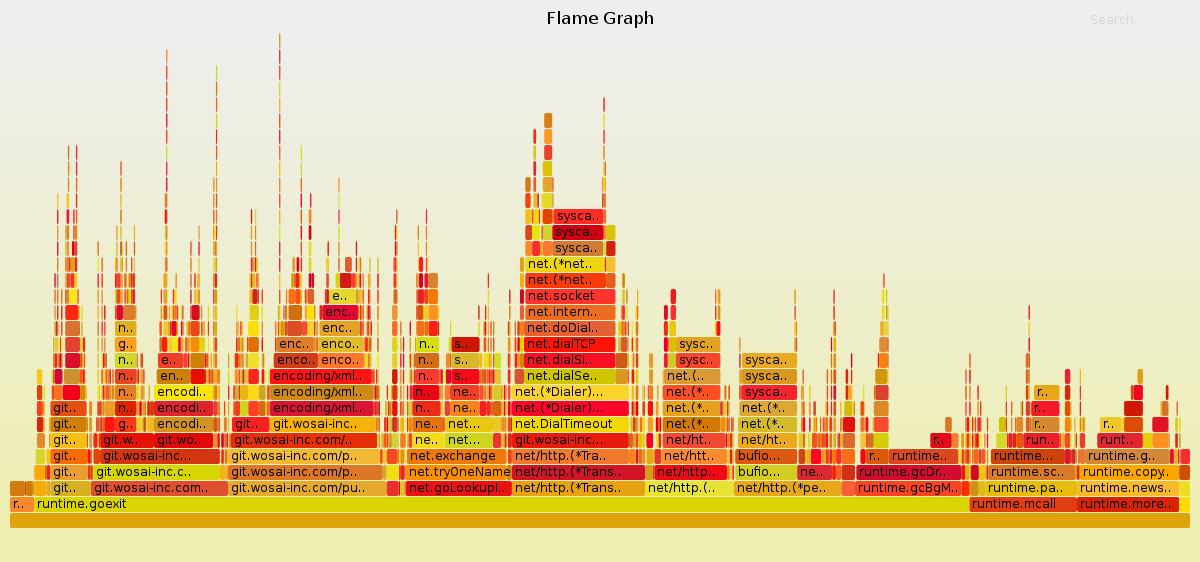
我们用go-torch对程序执行进行采样,并绘制火焰图,可以发现,占用执行时间比较多主要是xml的编码解码过程和net/http的网络过程,其中有一部分是DNS查询,也花费了很长的时间,我们用https://github.com/valyala/fasthttp重写了ali_mns的网络层,并且开源了这部分代码,在https://github.com/lujiajing1126/ali_mns,并且我们把一次取一条消息的逻辑改成批量取16条消息
优化以后,火焰图如下:
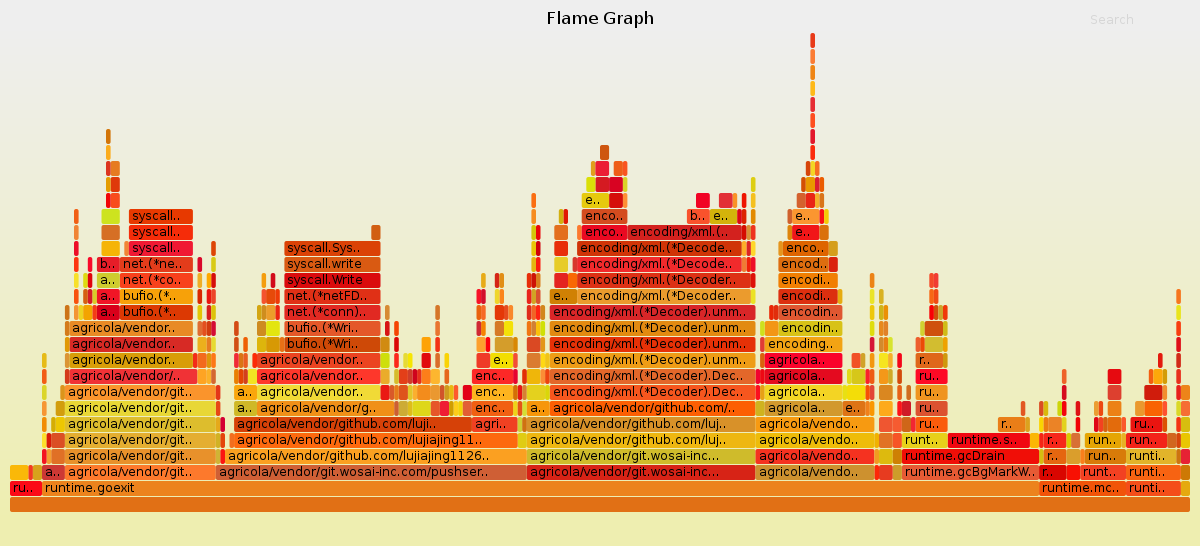
网络请求时间的占用比大大下降,xml的编解码过程占用显得十分突兀,目前也没有好的办法进行优化
在此之后,我们测试发现,框架的性能QPS从20提升到了200
从200到2000的努力
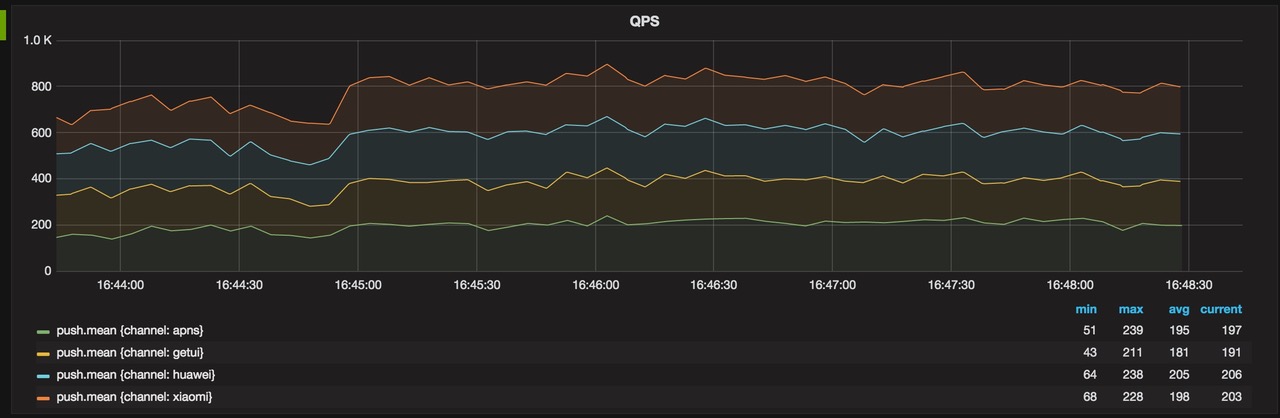
经过我们几天的优化,我们发现在代码层面上很难再做改进,从火焰图上面也能看到,但是框架的性能一直没有能够提高,我们始终在努力找办法以及原因
最近,有时间静下心来,测试研究如何提高QPS的方法,我发现,如果提高框架的broker并发数量,仍难提高QPS,进一步就发现了,原来是删除的逻辑是同步的,即在删除消息之前,没有办法接受新的消息
于是我们对broker的处理逻辑做了以下几个改动
1. 支持多个线程取消息
可以通过调节并发数量,启动指定数目的消息获取线程,并发获取消息
2. 独立的删除线程
把删除消息设置成异步,通过独立的删除消息线程执行删除消息逻辑
并且支持批量删除消息,在内存中维护一个列表,存储消息的句柄,一秒钟进行一次轮训批量删消息,或者消息积累到16条即删除
3. 调节mns的隐藏消息时长
我们增大mns的取出隐藏消息时长到5分钟,即认为5分钟内,某一条消息一定能被消费完
因为网络请求有消费时间的限制,所以可以合理的设置这一策略,来避免使用自适应消息时长的方法
通过如上的几种架构优化,我们成功在单个消息消费线程,10个并发worker的情况下把QPS提高到了2000
后来,我查阅sidekiq的性能指标时,发现sidekiq的作者同样也采用类似的方法来提高sidekiq的并发能力,详见http://www.mikeperham.com/2015/10/14/optimizing-sidekiq/
但他毕竟是ruby,再怎么优化也是呵呵